
はじめに
Dify のナレッジベース機能は非常に強力ですが、組織内に既存のベクトル DB や独自の検索インデックスがある場合、Dify 組み込みのナレッジに再アップロードするのは管理の二重化につながります。外部ナレッジベース API を使うことで、自前の検索システムをそのまま Dify のナレッジソースとして接続できます。
本記事では 外部ナレッジベース API の仕様 を満たす最小構成のサーバーを Flask で実装し、Dify と連携するまでの手順を紹介します。
今回は動作確認を目的としているため、固定のダミーレスポンスを返す実装としています。実際の RAG システムへの応用については こちらの記事 をご参照ください。
なぜ外部ナレッジベース API を使うのか
Dify 標準のナレッジベースはドキュメントをアップロードして管理する仕組みです。一方、すでに社内に独自の検索エンジンやベクトルストア(Elasticsearch、Qdrant、Weaviate など)が運用されている場合、同じドキュメントを Dify にも取り込むと管理箇所が分散します。
外部ナレッジベース API を使うと、Dify はアプリ側の検索結果をそのまま受け取れるため、データの一元管理が可能になります。また、Dify が対応していない検索ロジック(キーワード検索とベクトル検索のハイブリッド、独自の重み付けなど)を自由に実装できるのもメリットです。
トレードオフとして、API サーバーの運用コストが増える点と、認証トークンの管理が別途必要になる点があります。
外部ナレッジベース API の仕様
Dify の外部ナレッジベースは以下の仕様が求められます。
エンドポイント
POST /retrieval
リクエストヘッダー
| ヘッダー | 内容 | |—|—| | Authorization | Bearer <API_KEY> 形式の認証トークン | | Content-Type | application/json |
リクエストボディ
{
"knowledge_id": "ナレッジID",
"query": "検索クエリ",
"retrieval_setting": {
"top_k": 2,
"score_threshold": 0.5
}
}レスポンスボディ
{
"records": [
{
"content": "ドキュメントの内容",
"score": 0.95,
"title": "ドキュメントのタイトル",
"metadata": {
"path": "doc/path",
"description": "説明"
}
}
]
}Flask 実装
プロジェクト構成
external-knowledge/
├── app.py
├── requirements.txt
├── docker-compose.yml
└── Dockerfilerequirements.txt
flask==3.1.0app.py
Authorization ヘッダーの検証と、リクエストボディのパースを行います。top_k は Dify 側から渡された件数指定で、レスポンスのスライスに使います。
import os
from flask import Flask, request, jsonify
app = Flask(__name__)
API_KEY = os.environ.get("API_KEY", "your-api-key")
@app.route("/retrieval", methods=["POST"])
def retrieval():
auth = request.headers.get("Authorization", "")
if auth != f"Bearer {API_KEY}":
return jsonify({"error": "Unauthorized"}), 403
data = request.get_json()
query = data.get("query", "")
top_k = data.get("retrieval_setting", {}).get("top_k", 3)
# ここに実際の検索処理を実装する(今回はダミーレスポンス)
records = [
{
"content": f"'{query}' に関するサンプルドキュメントの内容です。",
"score": 0.95,
"title": "サンプルドキュメント",
"metadata": {
"path": "sample/doc.md",
"description": "サンプル用のダミーレスポンスです"
}
}
]
return jsonify({"records": records[:top_k]})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)Dockerfile
FROM python:3.12-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app.py .
EXPOSE 5000
CMD ["python", "app.py"]Dify との接続設定
Dify のネットワークへの接続方法は DifyとMCPを組み合わせてAIを構築する の記事を参考に、外部ナレッジ用コンテナを Dify の Docker ネットワークに接続します。
docker-compose.yml にサービスを追加する場合は以下のようになります。
services:
external-knowledge:
build: ./external-knowledge
environment:
- API_KEY=your-api-key
networks:
- docker_ssrf_proxy_network # Dify のネットワーク名に合わせて変更
networks:
docker_ssrf_proxy_network:
external: trueコンテナを起動します。
docker compose up -dDify への登録
1. 外部ナレッジベースを作成する
Dify の「ナレッジ」メニュー右上から「外部ナレッジベース連携 API」を選択します。
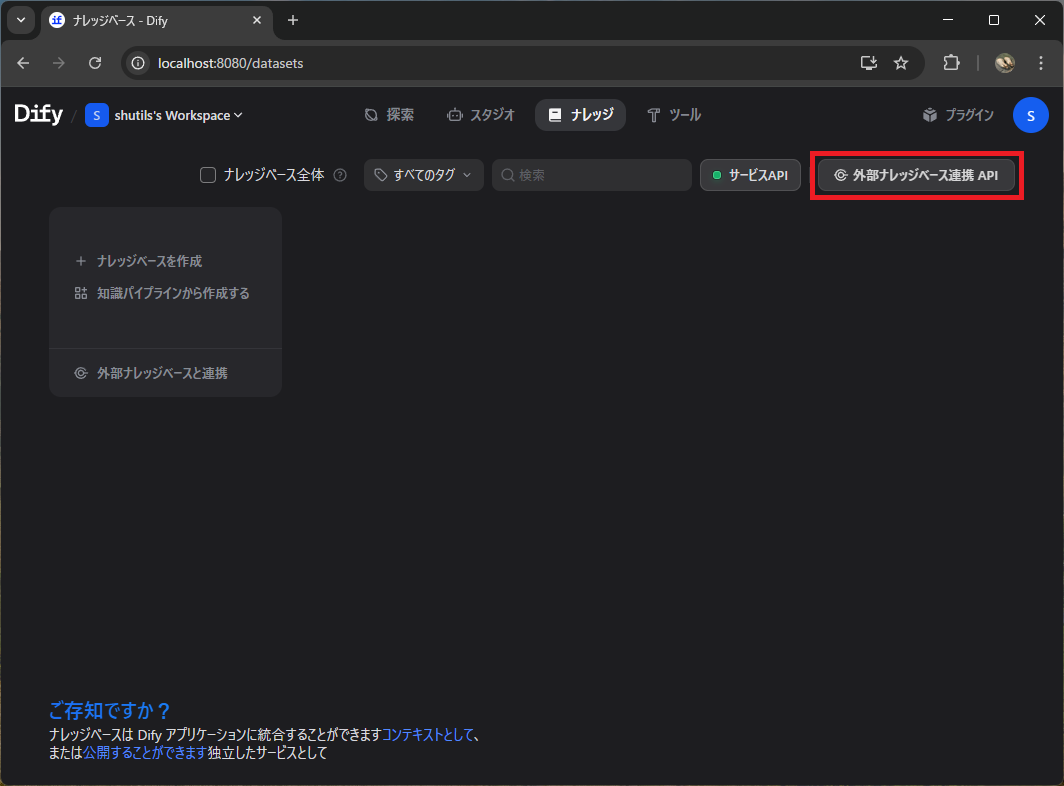
続いて「外部ナレッジベース連携 API を追加」をクリックします。
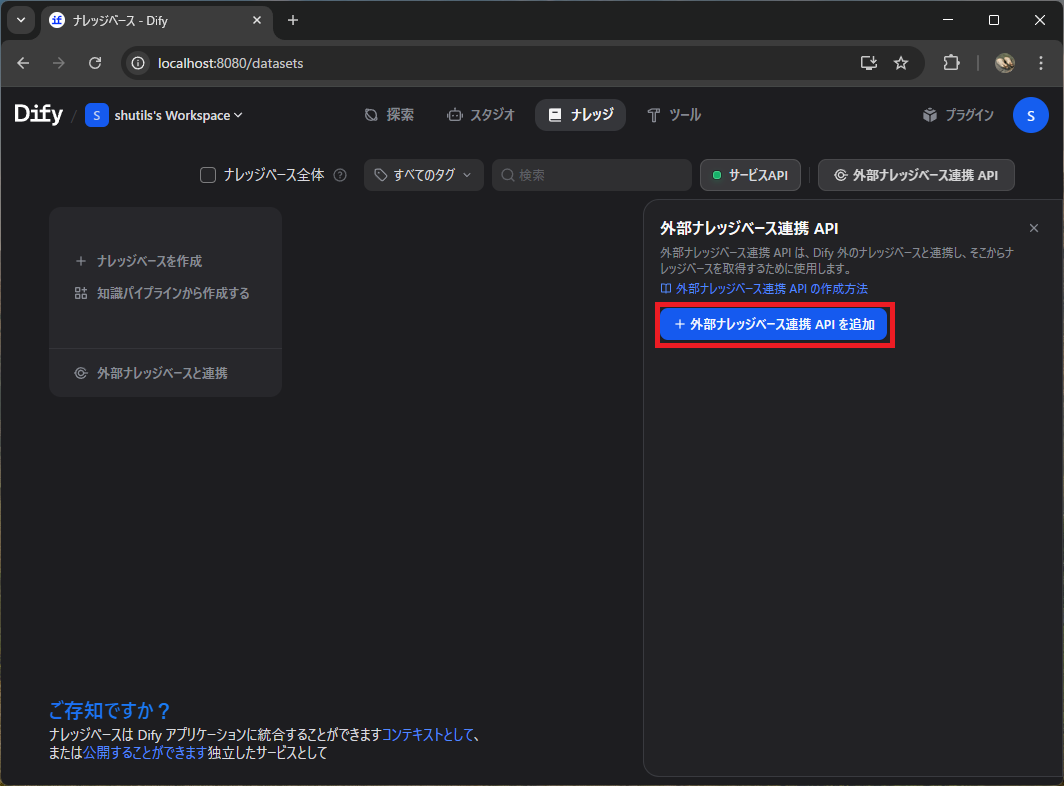
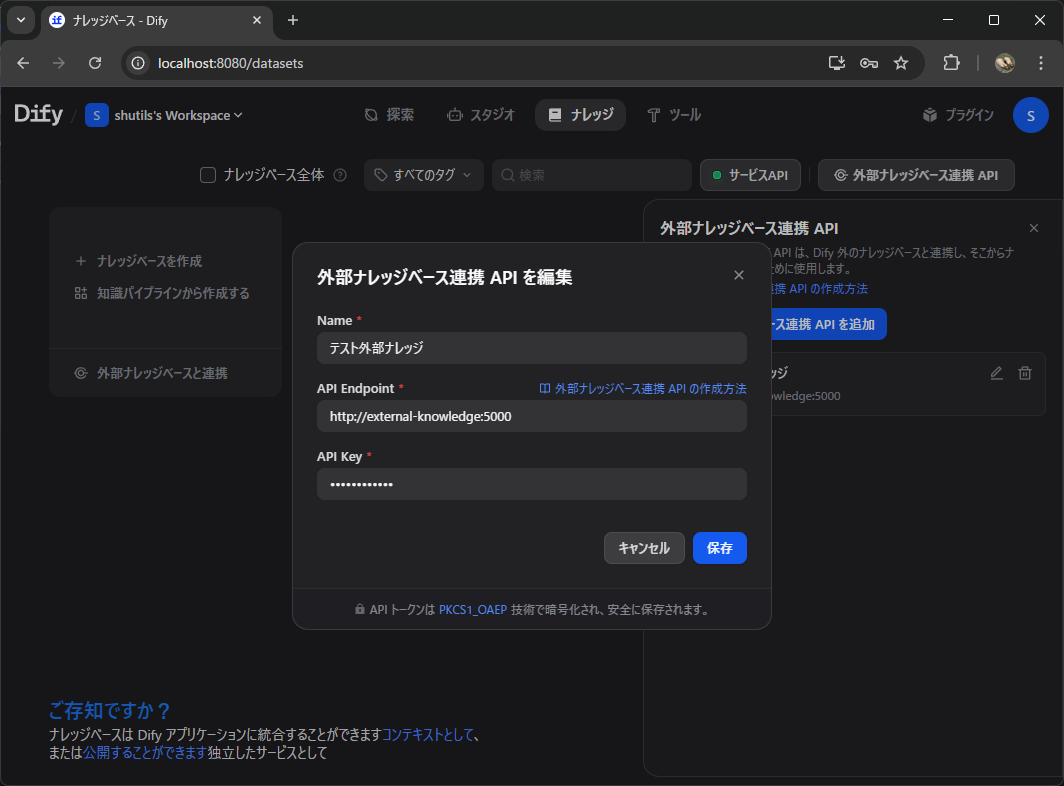
2. API 設定を入力する
以下の情報を入力します。
| 項目 | 値 |
|---|---|
| 外部ナレッジ API の名前 | 任意の名前 |
| API エンドポイント | http://external-knowledge:5000 |
| API キー | app.py の API_KEY に設定した値 |
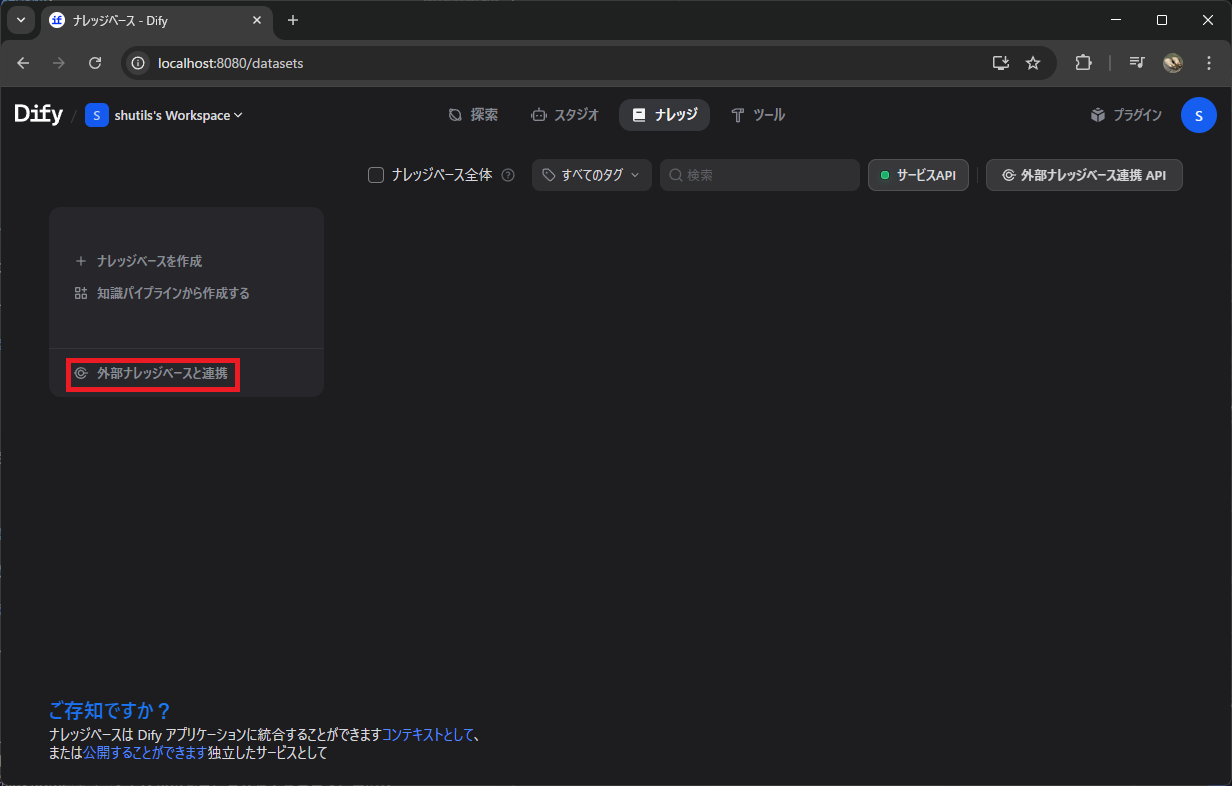
3. ナレッジとして登録する
外部ナレッジベースを作成した後、「ナレッジ」メニューの左側の「外部ナレッジベースと連携」を選択します。
4. 外部ナレッジベースの設定を入力する
以下の情報を入力します。
| 項目 | 値 |
|---|---|
| 外部ナレッジベース名 | 任意の名前 |
| 外部ナレッジベース連携 API | 2で作成した外部ナレッジベース連携 API |
| 外部ナレッジベース ID | 任意のID |
作成後に一覧に戻りますが、筆者の環境ではリロードしないと作成したナレッジが表示されませんでした。必要に応じてブラウザをリロードしてください。
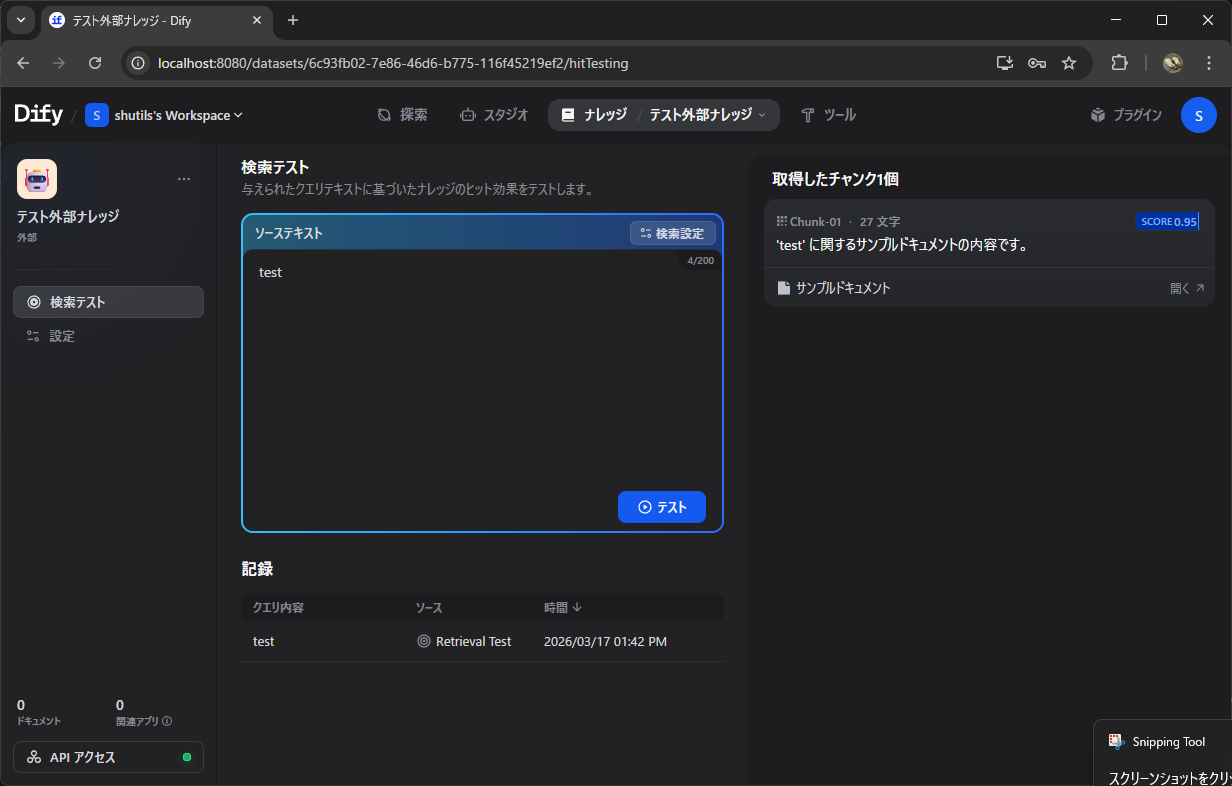
5. 検索テストを行う
作成したナレッジを開き、「検索テスト」タブを選択します。クエリを入力して「テスト」ボタンをクリックすると、app.py で定義したダミーレスポンスが表示されるはずです。
まとめ
Dify の外部ナレッジベース API を満たす最小構成の Flask サーバーを作成し、Dify と連携する手順を紹介しました。今回はダミーレスポンスを返す構成ですが、retrieval 関数内に実際の検索処理(ベクトル検索など)を実装することで、自前の RAG システムを Dify から利用できるようになります。
実際に試してみて気づいたのは、Dify のネットワーク設定さえ正しく行えばサーバー側の実装はシンプルで済む点です。 まずダミーレスポンスで接続を確認し、その後に検索ロジックを段階的に実装するアプローチを取ると、問題の切り分けがしやすくなります。 次は Weaviate などのベクトル DB を組み合わせた実際の RAG 実装を試してみたいと思います。


コメント