はじめに
業務の設計レビューや社内勉強会の資料で、フロー図を1枚だけ作りたい場面が頻繁にあります。draw.ioで真面目に書くほどではない、ラフでよいけれど見栄えはほしい、そんな温度感のときに画像生成AIに「フロー図を作って」と頼みたくなります。最近では日本語が得意なAIも増えてきましたが、業務で使えるツールには限りがあり、筆者の場合はM365 Copilotを使う環境でした。
ところが、画像生成AIで日本語のラベル入りフロー図を出力すると、ほぼ確実にラベルが崩れます。「ユーザー」が「ユーーザザ」になり、「ログイン」が見たことのない漢字の連なりになる、というのを過去半年で何十回も見てきました。画像を作るたびに「またダメか」となる、という流れを繰り返しているうちに、画像生成AIと別系統のマルチモーダルAIを組み合わせた解決策に落ち着いたため、本記事ではその4ステップのワークフローを紹介します。
本記事はM365 Copilotを使った環境で実際に運用している手順をもとにしています。画像生成とマルチモーダルチャットの両機能が揃っていれば同種のサービスでも同様に成立します。
なぜ画像生成AIは日本語を崩すのか
画像生成AIが日本語を崩すのは、モデルが「文字をピクセル列として描画している」ためです。テキストレンダラを内蔵しているわけではなく、訓練データに含まれる文字の見た目を学習した結果として、それっぽい字形を生成しています。
ここに日本語特有の事情が3つ重なります。
- 文字種が多い: ひらがな・カタカナ・漢字・数字・記号を合わせると、英数字・記号のみのラテン圏とは比べ物にならない量の字形パターンを覚える必要があります。一方で学習データに含まれる日本語の図表は相対的に少なく、頻出字形の学習が薄くなります。
- トークナイザの粒度: 多くの画像生成モデルは英語ベースのトークナイザで学習されており、日本語は1文字でも複数トークンに分解されることがあります。「フロー図」のような短い単語でも、モデル内部では字形と直接対応しないトークン列として扱われます。
- 小さい文字の生成が苦手: フロー図のラベルは図全体に対して小さなフォントになるため、ピクセル列としての解像度が足りず、画数の多い漢字は潰れて別の字形に化けます。
つまり、画像生成AIに日本語ラベルを直接書かせる構造そのものが、いまの世代のモデルでは無理筋です。代替手段としてMermaidやdraw.io、ExcalidrawのAI連携もありますが、デザインの自由度・余白の取り方・線のテイストといった「資料として並べたときの見栄え」では画像生成AI由来のラフなフロー図のほうが好み、という人も多いはずです。本記事のアプローチは、画像生成AIの「構造を一発で出す力」と、HTMLレンダラの「日本語を正しく描く力」を分業させる、というトレードオフ設計になっています。
4ステップの全体像
実際のワークフローは以下の4ステップです。
- フロー図の 構造を英語で指示する プロンプトを作る
- 画像生成AIに渡してフロー図を生成する
- 生成された画像をマルチモーダルAIに渡し、HTMLで再現させる
- ブラウザで開いてスクリーンショットを撮り、資料に貼り付ける
要点は 「画像生成AIには日本語を一切書かせない」 という割り切りです。日本語ラベルはステップ3のHTML側で正しく書き直すので、画像生成AIには形・配色・矢印の流れだけを担当してもらいます。
ステップ1: フロー図生成用プロンプトを作る
画像生成AIに渡すプロンプトは、英語で構造だけを記述します。日本語ラベルを入れると確実に崩れるため、ラベルもすべて英語のプレースホルダにしておきます。
たとえば「ユーザーがログインしてダッシュボードを見る」という流れを描く場合、以下のような構造化プロンプトを使います。
A clean, modern flowchart on a white background, drawn in a flat
illustration style. Five rounded rectangles connected by arrows,
arranged left to right.
Box 1 (blue): "STEP_USER"
Box 2 (green): "STEP_LOGIN"
Box 3 (green): "STEP_AUTH"
Box 4 (orange): "STEP_DASHBOARD"
Box 5 (gray): "STEP_LOG"
Arrows are thin, dark gray, with small arrowheads. No drop shadow,
no gradient, generous white margin.ポイントは3つあります。
- ラベルを
STEP_USERのようなアンダースコア区切りの英大文字にすることで、画像生成AIが「読みやすい英単語」として認識しやすくなります。日本語はもちろん、長い英文も小さく描かれると崩れがちなので、短いキーワード単位に分けます。 - スタイル指示を「flat illustration」「no drop shadow」「generous white margin」のように 引き算で書く ようにします。装飾を増やすほど線が太くなり、日本語に置き換えたときの余白が足りなくなるためです。
- 矢印の向きと並び順を明示します。「left to right」「top to bottom」のような順序語を入れると、後段のHTML化でも構造を読み取りやすくなります。
英語キーワードからのマッピングは、自分用にメモしておきます。
| プロンプト内のキー | 日本語ラベル(最終差し替え用) |
|---|---|
| STEP_USER | ユーザー |
| STEP_LOGIN | ログイン |
| STEP_AUTH | 認証サーバー |
| STEP_DASHBOARD | ダッシュボード |
| STEP_LOG | アクセスログ |
このマッピングはステップ3でAIにも渡すため、テキストファイルやメモアプリにそのまま貼り付けられる形にしておくと便利です。
ステップ2: 画像生成AIでフロー図を生成する
ステップ1のプロンプトを画像生成サービスに投げて、PNGを保存します。気に入った構造が出るまで何度かリトライするとよいでしょう。
注意:ステップ3でHTMLに変換することを前提にしているため、ラベルの英語が多少崩れていても問題ありません。重視するのは矢印の向き・ボックスの並び・配色のバランスです。
複数枚を出して比較するときは、以下の観点を見ます。
- 矢印の向きが指示通りか(左→右、上→下など)
- ボックス数が指示通りか(増減・重複がないか)
- 線が均一に描かれているか(途切れや極端な太さの違いがないか)
- 配色が資料の系統に合っているか
英語ラベルが多少崩れていても、人間が「あぁ、STEP_USERのことだな」と判別できれば十分です。完璧な構造を狙うより、構造が合っていて配色が好みの1枚を採用するほうが、トータルの工数は短くなります。
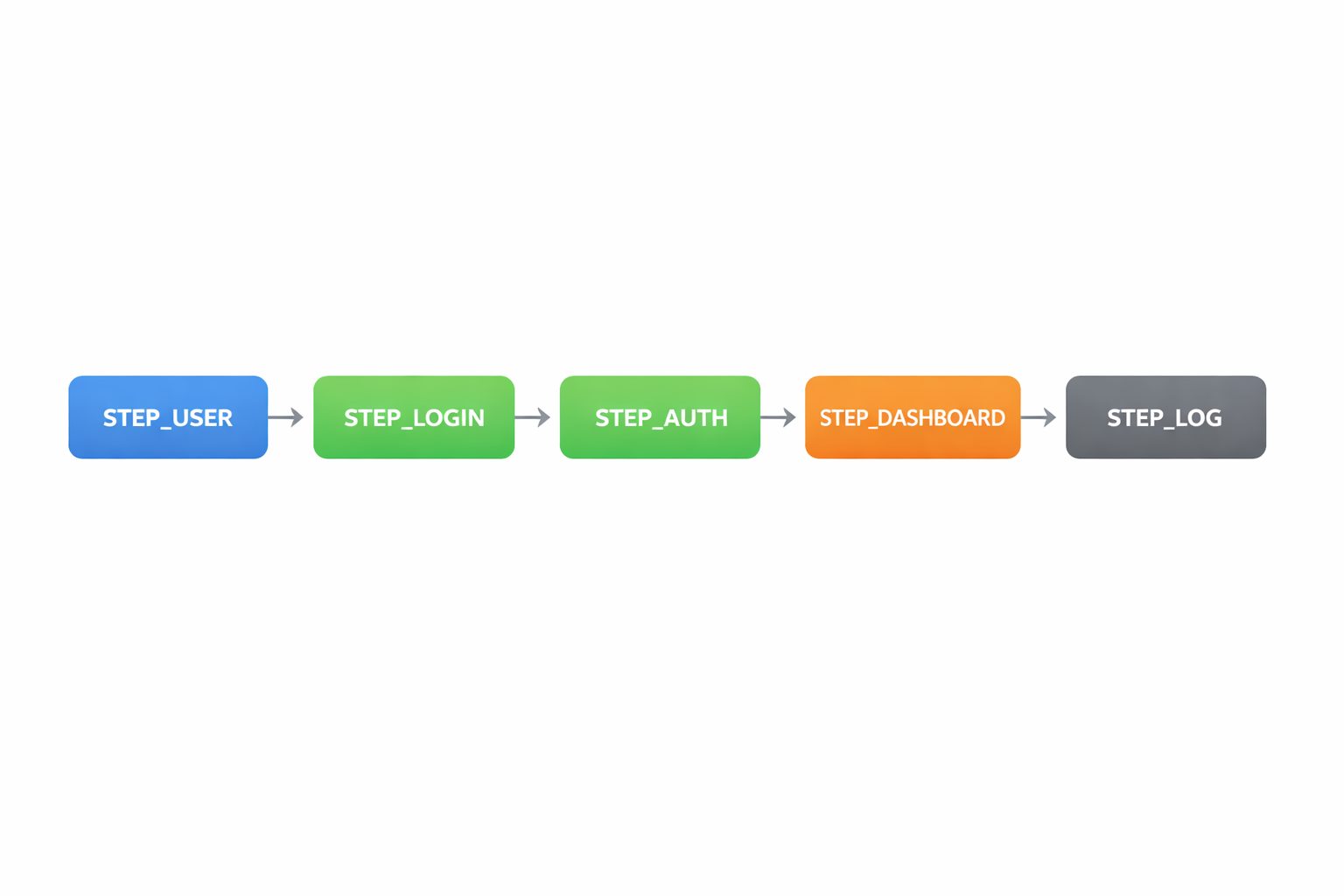
実際に生成された画像は以下のような感じになります。
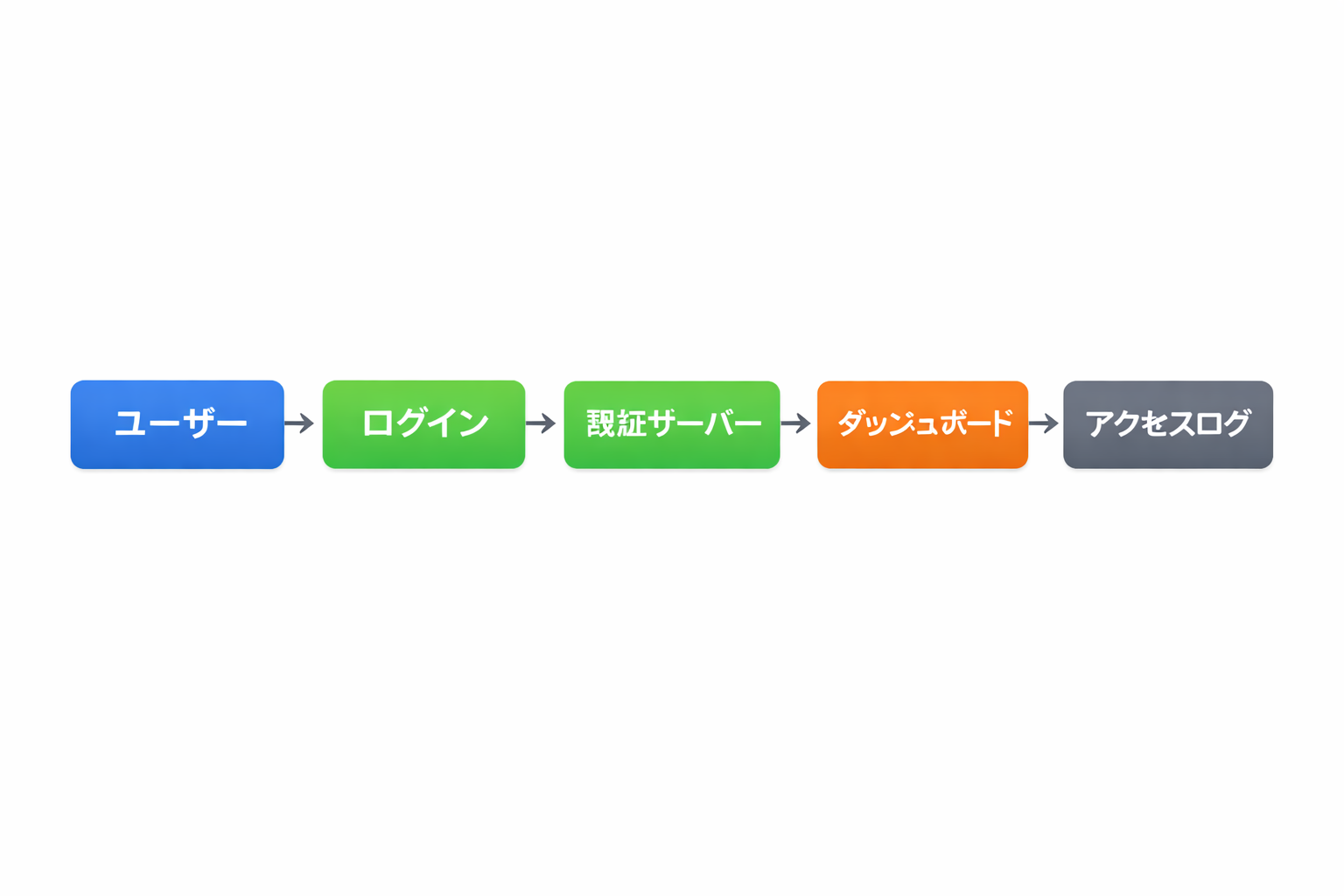
ちなみに日本語で作成させると以下のような感じになります。やはり文字が崩れて読めない部分が出てきます。
ステップ3: 生成画像をAIに渡してHTMLに変換する
ここからがこの手法の肝です。ステップ2で得た画像を、画像入力に対応したマルチモーダルAIに渡し、「同じ見た目をHTMLで再現してほしい。ラベルは差し替えて」と依頼します。
依頼用のプロンプトテンプレートは以下のような形にしています。
添付の画像と同じレイアウト・配色のフロー図を、HTMLとインライン
CSSで再現してください。以下の条件を守ってください。
- 画像内のラベル(STEP_USER, STEP_LOGIN, ...)を、下記の対応表に
従って日本語に差し替えること
- フォントは `'Noto Sans JP', 'Hiragino Sans', sans-serif` を指定
- 単一HTMLファイルで完結させ、外部CSSや画像を参照しない
- 背景は透過ではなく白(#FFFFFF)
- ビューポート幅 1280px を想定したサイズで配置
対応表:
- STEP_USER → ユーザー
- STEP_LOGIN → ログイン
- STEP_AUTH → 認証サーバー
- STEP_DASHBOARD → ダッシュボード
- STEP_LOG → アクセスログマルチモーダルAIは画像から「角丸長方形が5つ・矢印で連結・左から右」というレイアウト構造を読み取り、その情報をもとにHTMLを生成してくれます。配色も画像から推定してくれるため、Tailwindのようなクラス指定ではなくインラインCSSで色コードを直接書いてもらうほうが、後段の微調整がやりやすいです。
筆者の場合、flex で横並びにしたボックス群をSVGの矢印で繋ぐ構成が安定して返ってきます。返ってきたHTMLは、ラベルだけ違う同じ構造の別バリエーションを作るときの テンプレート としても流用できるため、業務で繰り返し使うフロー図のフォーマットを固めるのにも役立ちます。
注意:ラベル差し替えはAI任せにせず、必ず対応表として明文化します。画像内の崩れた英語ラベルから日本語ラベルへの推測をAIに任せると、似たキーワードに引きずられて誤訳・誤推測が起こります。
ステップ4: ブラウザで開いてスクリーンショットする
返ってきたHTMLを flow.html のような名前で保存し、ブラウザで開きます。スクリーンショットは以下の順序で撮るときれいに収まります。
- ブラウザのウィンドウをHTMLで指定したビューポート幅(例: 1280px)以上に広げる
- DevTools(ChromeならF12)を開き、Device Toolbarでビューポートを
1280 x 720等に固定する - DevToolsのコマンドメニュー(
Ctrl + Shift + P)でCapture full size screenshotを実行する
Capture full size screenshot を使うと、はみ出した領域も含めてページ全体をPNGで保存できるため、スクロールが発生する大きめのフロー図でも1枚画像で書き出せます。
スクリーンショットを資料に貼るときは、解像度を落としすぎないことが大切です。ステップ2の画像生成AI出力は、拡大すると線がガビガビになることが多いですが、HTML経由で再生成したスクリーンショットはベクター的なシャープさを保てるため、Keynote・PowerPoint・Notion・Confluenceいずれに貼っても見栄えが落ちにくくなります。
CLIで自動化したいときは、Playwrightの page.screenshot({ fullPage: true }) を使うと、HTMLを差し替えてバッチで複数枚生成する運用にも繋げやすいです。
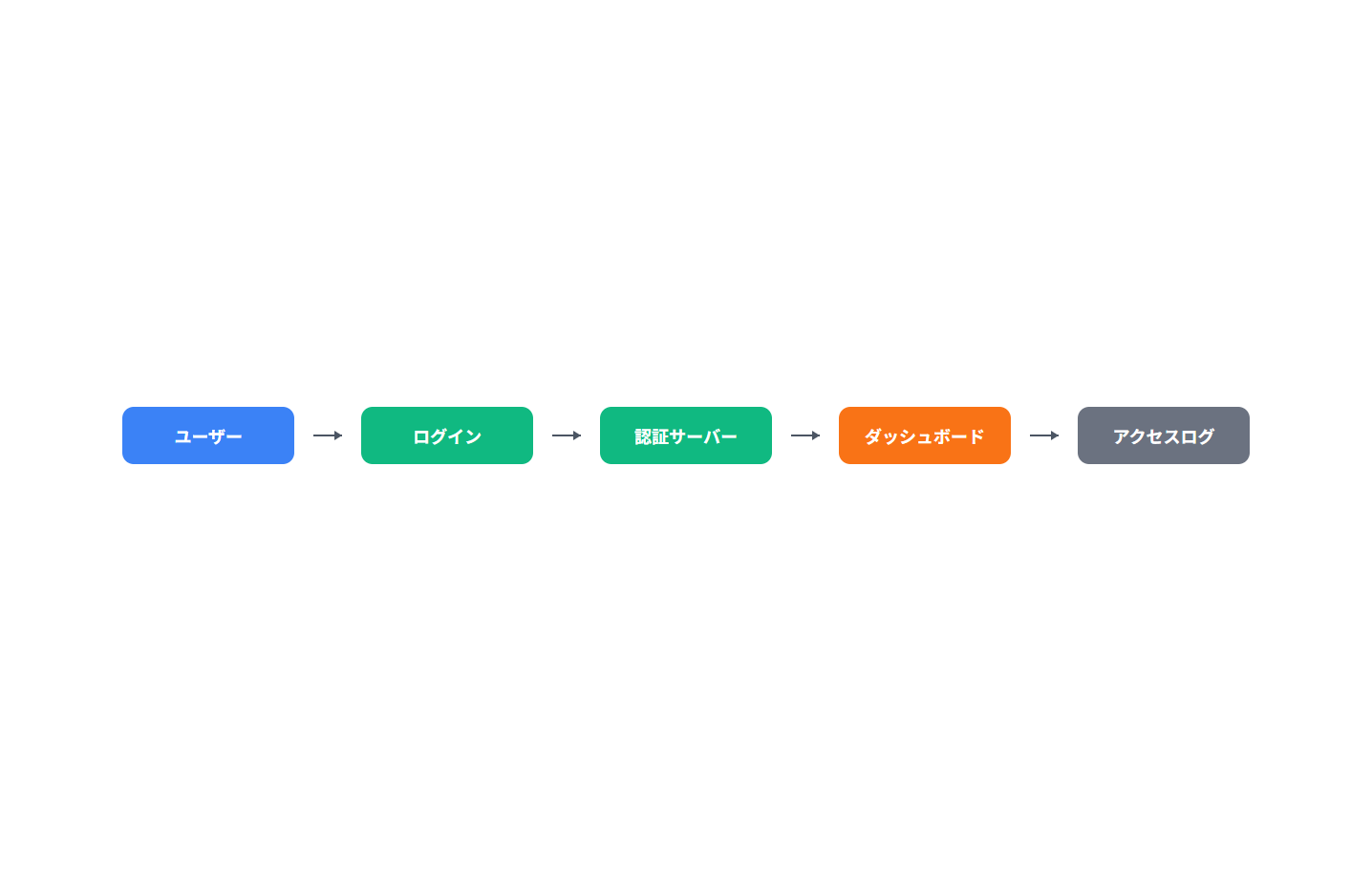
実際のスクリーンショットは以下のような感じになります。
ハマったポイント
ボックスの形がHTMLで再現できないケース
画像生成AIが描く「ちょっと歪んだ手書き風の角丸長方形」のような独特の質感は、HTMLで再現しようとすると平面的になります。質感を残したい場合は、ステップ2で出た画像をそのまま貼り、ラベル部分だけを 白い四角で塗りつぶし て、その上にHTMLで生成したラベルを重ねるという折衷案もあります。手間は増えますが、画像のテイストを残しつつ日本語を正しく入れられます。
矢印の本数が画像とずれる
生成画像が一見シンプルでも、実は分岐や合流があってAIが見落とすことがあります。HTML化したあとに矢印の本数を画像と見比べ、欠けている矢印を手で1〜2本足す、というレビュー工程を必ず挟むようにしています。
横並びが画面幅で折り返される
長いラベルを差し替えたとき、flex のままだと縮小されたり折り返されたりすることがあります。コンテナに min-width を指定するか、Flexboxではなくグリッドで明示的な列幅を指定してもらうと安定します。AIにHTMLを依頼するときに「ラベルが日本語に置き換わっても折り返しが起きないようにすること」と一文追加するだけでも結果が変わります。
まとめ
画像生成AIで日本語の文字化けに悩まされる場面は当面なくならないため、画像生成AIには構造だけを担当させ、ラベルの最終描画はHTMLレンダラに任せる、という分業構成に切り替えました。プロンプト作成→画像生成→HTML化→スクショの4ステップで運用すると、資料用のフロー図を10〜15分程度で1枚仕上げられるようになりました。
実際に運用してみて感じたのは、画像生成AIに「日本語を書かせない」と割り切ったことで、生成のリトライ回数が激減したことです。以前は「日本語ラベルが少しでも読めるもの」を求めて10枚以上リトライしていましたが、英語のプレースホルダだけにしたら2〜3枚目で採用候補が出るようになりました。
一方で、本手法は構造がシンプルな(おおむね10要素までの)フロー図で安定して機能します。要素が多い・分岐が複雑な場合は、画像生成AI側で構造そのものが破綻するケースが増えるため、最初からMermaidやdraw.ioに倒す判断も必要です。資料の温度感に合わせて「画像生成AI+HTML経由」と「コード生成系の図」を使い分けるのが、現時点では現実的な落とし所だと感じています。
次は、今回手作業で行っている部分を各種ツールの連携で自動化する方法を模索してみたいと思います。

コメント