はじめに
以前、Dify の外部ナレッジベース API を Flask で実装して、Dify から自前の検索システムを呼び出す構成を試しました。 その後、PPTX や Excel のようなオフィス文書をナレッジとして扱う場面で、単に本文だけを返すと「どのスライドの内容なのか」「どのシートを見ればよいのか」が追いづらいことがありました。
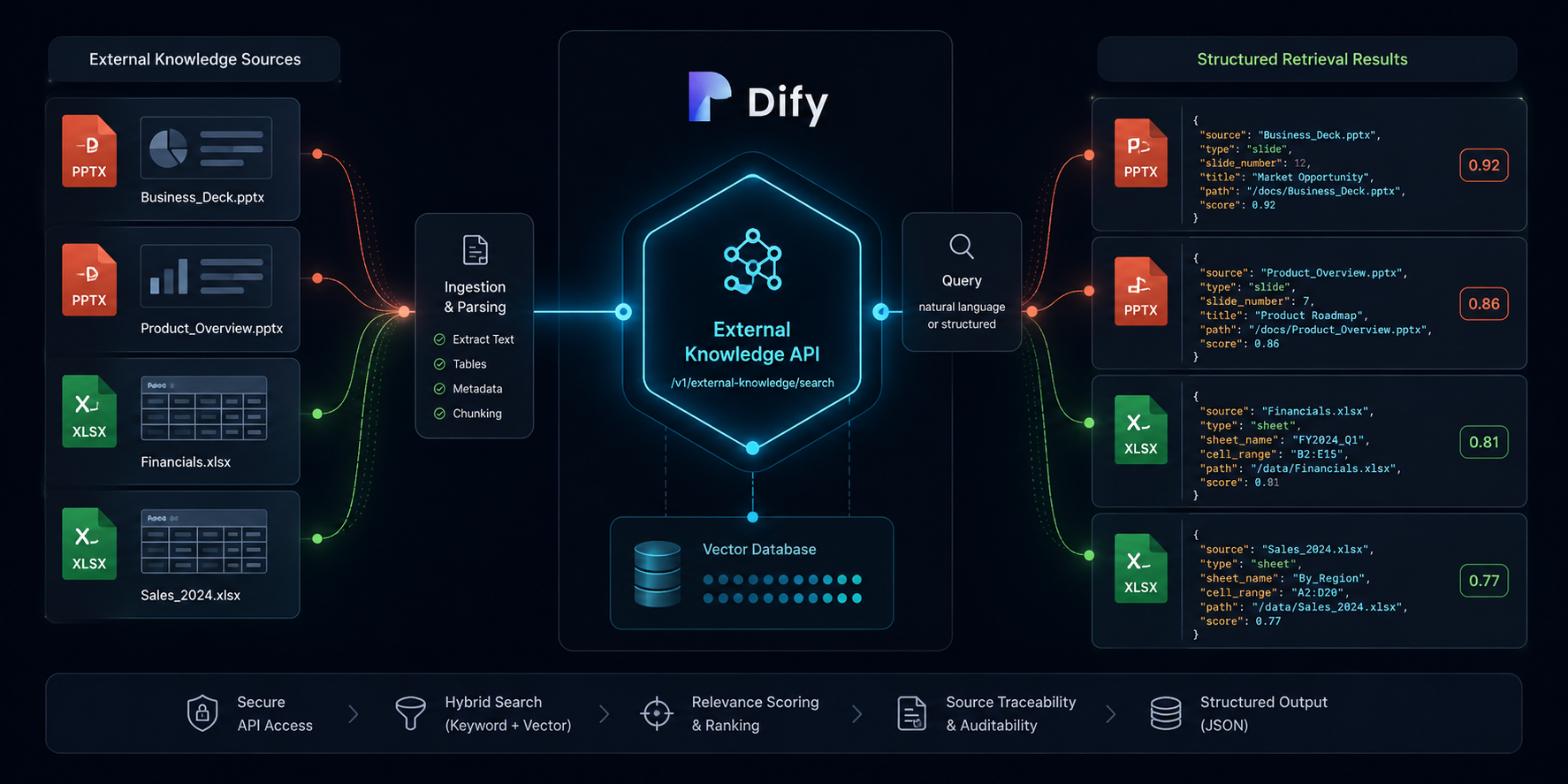
特にプレゼン資料は、同じキーワードが複数スライドに出てくることが多く、LLM の回答だけでは元資料を確認するときに探し直しが発生します。 本記事では、Dify の外部ナレッジ API の metadata を使って、PPTX のスライド番号や Excel のシート名を検索結果に含める方法を紹介します。
ベースにしている実装は /home/shutils/lab/external-knowledge に置いている Flask アプリです。 この記事では PPTX をスライド単位に分割して返す実装を中心に説明し、Excel については同じ考え方でシート名を持たせる拡張例を示します。 なお、今回は metadata の扱いを分かりやすくするため、ベクトル DB は使わずにシンプルなキーワード検索で構成しています。
なぜ本文だけでは足りないのか
Dify の外部ナレッジ API は、外部サービスが検索したチャンクを records として返す仕組みです。 content に本文、title に文書タイトル、score に関連度を入れれば、Dify はその内容を LLM のコンテキストとして利用できます。
ただ、PPTX や Excel は Markdown ファイルと違い、ファイルパスだけでは参照位置が粗すぎます。 たとえば sample.pptx がヒットしたことは分かっても、元資料を開いてから該当スライドを探す必要があります。 Excel でも sales.xlsx がヒットしただけでは、Summary シートなのか 2026-06 シートなのかを確認し直すことになります。
そこで、検索結果のチャンクごとに以下のような情報を metadata に持たせます。
| ファイル種別 | チャンクの単位 | metadata に入れたい値 |
|---|---|---|
| PPTX | スライド | path, slide_number |
| Excel | シートまたは行範囲 | path, sheet_name, row_start, row_end |
| ページ | path, page_number |
|
| Markdown | 見出し単位 | path, heading |
Dify の公式ドキュメントでも、外部ナレッジ API の records[].metadata は任意のキーバリューペアを保持する object として定義されています。 注意点として、metadata を返す場合は {} のようなオブジェクトにする必要があり、null を返すと検索パイプラインでエラーになる可能性があります。
外部ナレッジ API のレスポンス構造
外部ナレッジ API のエンドポイントは POST /retrieval です。 Dify から送られる検索クエリを受け取り、検索結果を次のような JSON で返します。
{
"records": [
{
"content": "スライドから抽出した本文",
"score": 0.95,
"title": "sample.pptx - slide 1",
"metadata": {
"path": "sample.pptx",
"slide_number": 1
}
}
]
}ポイントは、metadata が Dify の検索結果に紐づく補助情報として残ることです。 LLM に渡す本文の中心は content ですが、検索結果や参照元を後で確認したい場合に metadata が役立ちます。
外部ナレッジ側の実装では、検索インデックスに登録する時点でメタデータを持たせてもよいですし、今回のようにファイルを読み込んで検索結果を作るときに付与してもかまいません。 どちらの場合でも、Dify に返す最終的な records の各要素に metadata を入れるのが重要です。
サンプル構成
今回参照しているサンプルは、以下の構成です。
external-knowledge/
├── app.py
├── Dockerfile
├── docker-compose.yml
├── requirements.txt
└── knowledge/
└── sample.pptxdocker-compose.yml では、knowledge ディレクトリを読み取り専用でコンテナにマウントしています。
services:
external-knowledge:
build: .
environment:
- API_KEY=your-api-key
- KNOWLEDGE_DIR=/knowledge
volumes:
- ./knowledge:/knowledge:ro
ports:
- "5000:5000"Dify のコンテナからこの API を呼び出す場合は、Dify が使っている Docker ネットワークに external-knowledge を参加させます。 サンプルの docker-compose.yml には、Dify の docker_ssrf_proxy_network に接続するためのコメントも残しています。
# networks:
# - docker_ssrf_proxy_network # Dify のネットワーク名に合わせて変更外部ナレッジ API の登録時には、Dify 側の API エンドポイントに http://external-knowledge:5000 のようなベース URL を指定します。 Dify は登録したベース URL に /retrieval を付けてリクエストします。
PPTX を MarkItDown でスライド単位にする
PPTX の本文抽出には MarkItDown を使います。 MarkItDown は PowerPoint などのオフィス文書を Markdown 風のテキストに変換できるため、ファイル形式ごとの読み取り処理をアプリ側に増やしすぎずに済みます。
今回のサンプルでは、変換結果に含まれるスライド番号のコメントを使ってチャンクを分けます。 たとえば <!-- Slide number: 1 --> のようなマーカーを見つけ、番号と本文を組にして扱います。
import re
from markitdown import MarkItDown
SLIDE_MARKER_RE = re.compile(r"<!--\s*Slide number:\s*(\d+)\s*-->\s*")
def _conversion_text(result):
return getattr(result, "text_content", None) or getattr(result, "markdown", None) or str(result)MarkItDown の戻り値はバージョンや変換対象によってプロパティ名が変わる可能性があります。 そのため、ここでは text_content、markdown、文字列表現の順に見ています。
次に、Markdown 化された本文をスライドごとに分割します。
def _split_pptx_slides(markdown):
parts = SLIDE_MARKER_RE.split(markdown)
if len(parts) == 1:
content = markdown.strip()
return [(None, content)] if content else []
slides = []
for index in range(1, len(parts), 2):
slide_number = int(parts[index])
content = parts[index + 1].strip()
if content:
slides.append((slide_number, content))
return slidesマーカーが見つからない場合は、ファイル全体を 1 つのチャンクとして扱います。 この場合は slide_number を付けず、path だけで参照元を示します。 スライド番号が取れる場合だけ metadata.slide_number を付けるようにしておくと、変換結果の差分にも対応しやすくなります。
実際に PPTX を読み込む処理は、次のように MarkItDown に寄せます。
def _extract_pptx_slides(path, md):
result = md.convert(path)
markdown = _conversion_text(result)
return _split_pptx_slides(markdown)この形にしておくと、PPTX だけ特別扱いする範囲を小さくできます。 将来的に PDF や Word を同じ外部ナレッジ API に載せる場合も、まず MarkItDown でテキスト化し、その後にファイル種別ごとのメタデータを付ける、という流れにそろえられます。
metadata を付けて records を作る
スライド本文を取り出したら、Dify に返す records の形へ変換します。 記事で紹介する実装では、PPTX ファイルごとに MarkItDown で本文を取り出し、スライドごとに metadata を付けています。
def _load_pptx_records():
md = MarkItDown()
records = []
for path in _pptx_paths():
relative_path = os.path.relpath(path, KNOWLEDGE_DIR)
try:
slides = _extract_pptx_slides(path, md)
except Exception as exc:
app.logger.warning("Failed to convert PPTX %s: %s", path, exc)
continue
for slide_number, content in slides:
metadata = {
"path": relative_path,
"source": path,
}
if slide_number is not None:
metadata["slide_number"] = slide_number
records.append(
{
"content": content,
"title": f"{relative_path} - slide {slide_number}"
if slide_number is not None
else relative_path,
"metadata": metadata,
}
)
return recordspath にはナレッジディレクトリからの相対パスを入れています。 これは Dify の画面や回答で見せることを想定した値です。 一方、source にはサーバー上の実パスを入れていますが、外部に見せる必要がない場合は返さないほうが安全です。
個人的には、Dify に返す metadata は次のように分けると管理しやすいです。
| キー | 用途 | ユーザーに見せるか |
|---|---|---|
path |
文書の相対パス | 見せる |
slide_number |
PPTX のスライド番号 | 見せる |
sheet_name |
Excel のシート名 | 見せる |
source |
サーバー内部の実パス | 基本は見せない |
updated_at |
インデックス更新日時 | 必要に応じて見せる |
今回のサンプル PPTX では、3 枚のスライドが次のようなレコードになります。
{
"content": "Page 1\n吾輩\nわがはい\nは猫である。名前はまだ無い。",
"title": "sample.pptx - slide 1",
"metadata": {
"path": "sample.pptx",
"slide_number": 1
},
"score": 1.0
}実際の app.py では、検索クエリに対する簡易スコアリングを行ったあと、score を足して Dify に返しています。
def _retrieve_records(query, top_k):
scored_records = []
for record in _load_pptx_records():
score = _score_record(record, query)
if score <= 0:
continue
scored_record = dict(record)
scored_record["score"] = score
scored_records.append(scored_record)
scored_records.sort(key=lambda record: record["score"], reverse=True)
return scored_records[:top_k]このスコアリングはサンプル用の単純なキーワード一致です。 今回は全体像を追いやすくするため、ベクトル DB の準備や埋め込み生成の処理は省いています。 本番用途では、ベクトル検索や BM25、ハイブリッド検索などで得られたスコアを 0 から 1 の範囲に正規化して返すほうがよいです。
curl で動作確認する
アプリを起動します。
docker compose up --buildヘルスチェックは GET /health で確認できます。
curl http://localhost:5000/health検索 API は POST /retrieval です。 Authorization ヘッダーには、docker-compose.yml の API_KEY と同じ値を Bearer トークンとして指定します。
curl -X POST http://localhost:5000/retrieval \
-H 'Authorization: Bearer your-api-key' \
-H 'Content-Type: application/json' \
-d '{
"knowledge_id": "office-documents",
"query": "吾輩",
"retrieval_setting": {
"top_k": 3,
"score_threshold": 0.0
}
}'レスポンスでは、records の各要素に metadata.slide_number が含まれます。
{
"records": [
{
"content": "Page 1\n吾輩\nわがはい\nは猫である。名前はまだ無い。",
"score": 1.0,
"title": "sample.pptx - slide 1",
"metadata": {
"path": "sample.pptx",
"slide_number": 1
}
}
]
}Dify から見ると、これは通常の外部ナレッジの検索結果です。 参照元を回答本文に必ず出したい場合は、アプリ側のプロンプトだけでなく、外部ナレッジ側の content に [source: sample.pptx slide 1] のような短い出典行を含める方法もあります。 一方で、検索結果の管理やログ上で参照元を追う目的であれば、metadata.path と metadata.slide_number を持たせるだけでも十分に扱いやすくなります。
Excel のシート名に応用する
Excel でも考え方は同じです。 PPTX ではスライド単位でチャンクを作りましたが、Excel ではシート単位、テーブル単位、または行範囲単位でチャンクを作ります。
たとえば openpyxl を使う場合、シートごとにテキストを作り、metadata.sheet_name を持たせます。
from openpyxl import load_workbook
def _extract_xlsx_sheets(path):
workbook = load_workbook(path, read_only=True, data_only=True)
records = []
for sheet in workbook.worksheets:
rows = []
for row in sheet.iter_rows(values_only=True):
values = [str(value) for value in row if value is not None]
if values:
rows.append("\t".join(values))
content = "\n".join(rows).strip()
if not content:
continue
records.append(
{
"content": content,
"title": f"{os.path.basename(path)} - {sheet.title}",
"metadata": {
"path": os.path.basename(path),
"sheet_name": sheet.title,
},
}
)
return recordsシート単位は実装が簡単ですが、1 シートが大きい場合はチャンクが大きくなりすぎます。 その場合は 20 行や 50 行ごとに分割し、row_start と row_end を追加します。
{
"content": "2026-06\t売上\t123000\n2026-06\t原価\t81000",
"title": "sales.xlsx - Summary rows 1-50",
"metadata": {
"path": "sales.xlsx",
"sheet_name": "Summary",
"row_start": 1,
"row_end": 50
}
}このようにしておくと、回答後に「sales.xlsx の Summary シート 1-50 行目を確認する」といった導線を作れます。 LLM にとっても、sheet_name があることで「これは月次集計のシートに由来する情報だ」と判断しやすくなります。
Dify 側で使うときの注意点
metadata は検索条件にも使えるが UI には制約がある
Dify の外部ナレッジ API には metadata_condition というリクエスト項目があります。 これは metadata の値で外部ナレッジ側の検索を絞り込むための条件です。
ただし、2026 年 6 月時点の公式ドキュメントでは、metadata_condition は API には渡されるものの、ユーザーが UI から設定するための画面は提供されていないと説明されています。 そのため、まずは「検索結果に参照元情報を付ける」目的で metadata を使い、フィルタリングはアプリ側の必要に応じて実装するのが現実的です。
metadata に入れる値は短く保つ
metadata は便利ですが、何でも入れる場所ではありません。 LLM に渡す本文は content に置き、metadata には参照元を特定するための短い値を入れるようにします。
避けたほうがよい例は、シート全体の説明文や巨大な JSON を metadata に入れることです。 検索結果として扱いやすい粒度にするには、path, slide_number, sheet_name, page_number のような識別子を中心にするのが無難です。
内部パスや機密情報を返さない
サンプル実装では source にサーバー上の実パスを入れています。 ローカル検証では便利ですが、Dify の画面やログ、アプリの回答に露出する可能性を考えると、本番では相対パスや文書 ID に置き換えたほうが安全です。
{
"metadata": {
"path": "proposal/sample.pptx",
"slide_number": 3,
"document_id": "doc-20260604-001"
}
}このように、ユーザーに見せても問題ない値だけを返す設計にしておくと、後からプロンプトや画面表示を変えるときにも扱いやすくなります。
参考リンク
まとめ
Dify の外部ナレッジ API では、records[].metadata に任意の補助情報を入れられます。 PPTX なら slide_number、Excel なら sheet_name や row_start / row_end を持たせることで、LLM の回答から元資料へ戻る導線を作りやすくなります。
今回の作業で改めて感じたのは、RAG の使いやすさは検索精度だけでなく、回答後に人間が元資料を確認できるかにも大きく左右されるという点です。 本文だけを返す外部ナレッジから一歩進めて、ファイル種別ごとの位置情報を metadata に載せておくと、Dify を社内資料検索や議事録検索に使うときの実用性がかなり上がります。
コメント