はじめに
業務で、CIのジョブが失敗したときや特定の条件を満たしたときに、Jiraのチケットを自動で起票する仕組みを作る機会がありました。 チケットのタイトルや本文はリポジトリ内のMarkdown(テンプレートやジョブの出力)から組み立てるのですが、いざ Jira REST API に投げてみると、本文の見出しやコードブロックがそのままプレーンテキストとして表示されてしまい、体裁がまったく崩れてしまいました。
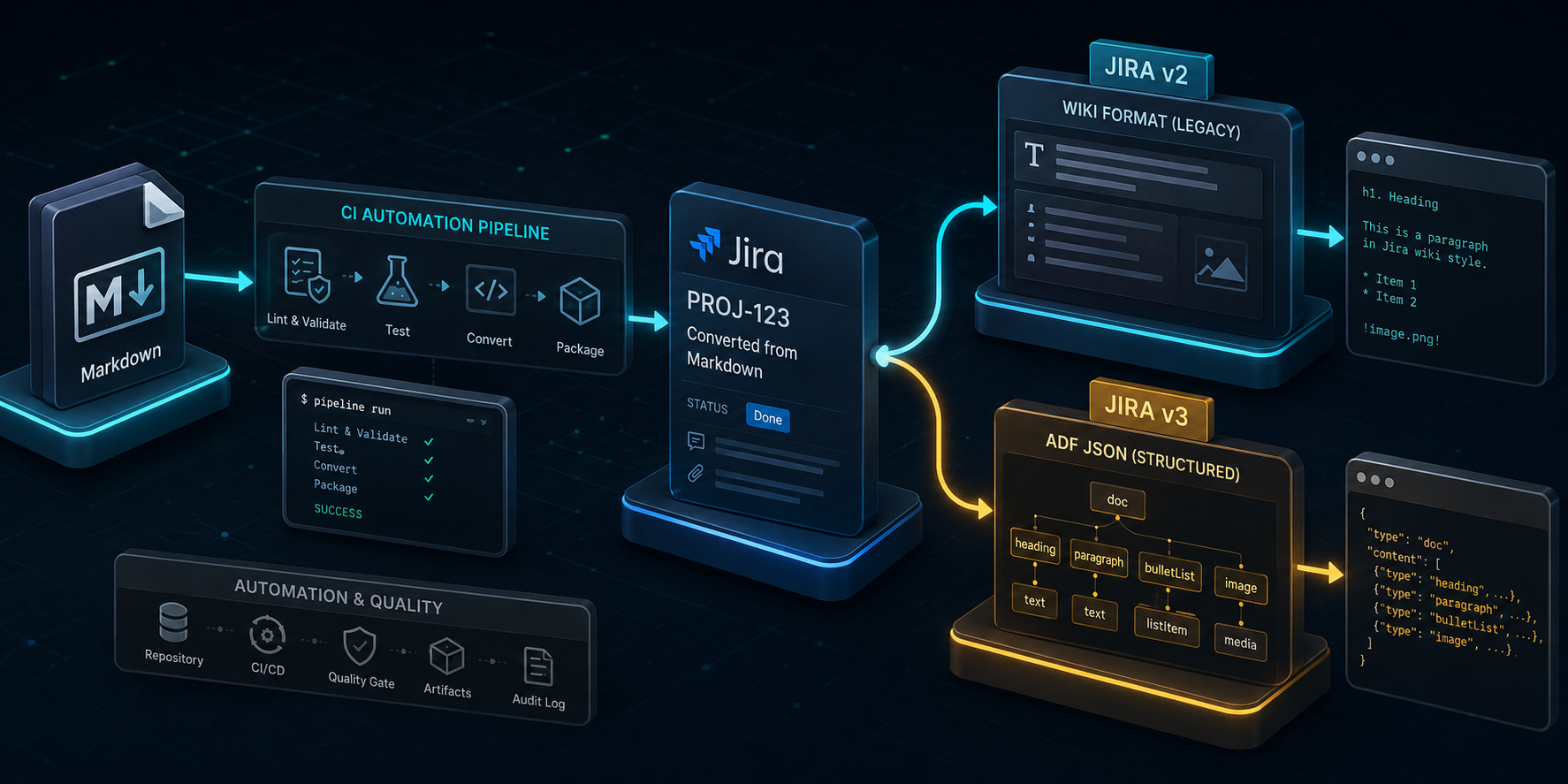
調べていくと、原因は Jira REST API のバージョン(v2 と v3)によって本文フィールドに渡すフォーマットが根本的に異なる、という点にありました。この差分に気づかず半日ほど溶かしたため、同じところでハマる人が出ないように記録しておきます。
本記事では、CIからJiraチケットを作成する際に、Markdownの本文を API バージョンごとにどう変換したか(v2 は pandoc、v3 は Atlaskit)を手順とともに紹介します。
なぜ本文の変換が必要なのか
Jira の REST API でチケットを作るとき、本文(description フィールド)に Markdown をそのまま文字列で渡しても、見出しやコードブロックは整形されません。これは、Jira が Markdown を本文フォーマットとして解釈しないためです。
さらに厄介なのが、受け付けるフォーマットが API のバージョンで変わる点です。
| API バージョン | エンドポイント例 | description の形式 |
変換に使ったツール |
|---|---|---|---|
| v2 | /rest/api/2/issue |
Jira Wiki 記法(テキスト) | pandoc |
| v3 | /rest/api/3/issue |
ADF(Atlassian Document Format、JSON) | Atlaskit |
v2 は h1. や {code} といった独自の Wiki 記法のテキスト を渡します。一方、Cloud 版で主流の v3 は ADF(Atlassian Document Format)という JSON 構造 を渡す必要があります。同じ Markdown を起点にしていても、出力先がテキストと JSON で別物になるため、変換処理を 2 系統用意することになりました。
代替案の検討
当初は「自前で Markdown をパースして Wiki 記法に置換する」案も考えました。しかし、ネストしたリストやテーブル、コードブロック内のエスケープまで正しく扱おうとすると、正規表現ベースの置換ではすぐ破綻します。メンテナンスコストを考えると、変換は実績のあるツールに任せたほうがよいと判断し、v2 は pandoc、v3 は Atlaskit のライブラリを使う構成にしました。
使用環境
- Jira: Cloud(v3)と Data Center(v2)の両方を対象
- pandoc: 3.x 系
- Node.js: 20 LTS(Atlaskit の変換スクリプト用)
Jira Cloud は v3 が標準ですが、社内には v2 のみで運用している Data Center 環境も残っていたため、両対応が必要でした。
v2 の場合:pandocでWiki記法に変換する
v2 の description は Jira Wiki 記法のテキストです。pandoc は出力フォーマットとして jira をサポートしているため、Markdown から一発で変換できます。
1. Markdown を Wiki 記法に変換する
# Markdown を Jira Wiki 記法へ変換する
pandoc -f markdown -t jira body.md -o body.jira-t jira が肝で、これだけで見出しは h2.、コードブロックは {code}、テーブルは ||見出し|| といった Wiki 記法に変換されます。CI のステップでは、出力をそのまま変数に取り込みます。
# 変換結果を環境変数に格納する
JIRA_BODY="$(pandoc -f markdown -t jira body.md)"2. API にチケット作成リクエストを送る
v2 では description に変換後のテキストをそのまま入れます。
curl -s -X POST "https://jira.example.com/rest/api/2/issue" \
-H "Authorization: Bearer ${JIRA_TOKEN}" \
-H "Content-Type: application/json" \
--data "$(jq -n \
--arg summary "CI失敗: ${BUILD_NAME}" \
--arg desc "$JIRA_BODY" \
'{fields: {project: {key: "OPS"}, issuetype: {name: "Bug"}, summary: $summary, description: $desc}}')"ここでのポイントは、本文を JSON に埋め込む際に jq -n --arg を使い、改行やダブルクオートのエスケープを jq に任せていることです。シェルで文字列連結すると、Wiki 記法に含まれる記号で JSON が壊れやすくなります。
注意点として、JIRA_TOKEN は CI のシークレット機能から渡すようにします。set -x やデバッグログで curl のヘッダーが出力されると認証情報が漏れるため、ログのマスク設定も合わせて確認しておくと安心です。
v3 の場合:AtlaskitでADFに変換する
v3 の description は JSON 形式の ADF(Atlassian Document Format)です。テキストではなくドキュメントツリーを組み立てる必要があるため、pandoc の jira 出力はそのまま使えません。ここでは Atlassian 公式の Atlaskit が提供する @atlaskit/editor-markdown-transformer を使いました。
1. 変換ライブラリを導入する
Markdown から ADF への変換には、Atlaskit のエディタ系パッケージを利用します。
npm install @atlaskit/editor-markdown-transformerMarkdownTransformer の parse() を呼ぶと、Markdown の見出し、箇条書き、装飾などが type: "doc" を起点にしたドキュメントオブジェクトへ変換されます。
Atlaskit のエディタ系パッケージは依存関係が比較的大きいため、CI のたびに毎回インストールすると時間が伸びやすいです。実運用では Node.js のバージョンを固定し、パッケージキャッシュを有効にしておくと安定します。
2. Markdown を ADF に変換するスクリプト
CI から呼べるよう、Markdown を受け取って ADF を標準出力に吐くスクリプトを用意しました。
// md2adf.mjs - Markdown を読み取って ADF(JSON) を出力する
import fs from "node:fs";
import { MarkdownTransformer } from "@atlaskit/editor-markdown-transformer";
// 引数で渡されたファイルから Markdown を読み込む
const markdown = fs.readFileSync(process.argv[2], "utf8");
// Markdown を ADF(JSON) のドキュメント構造へ変換する
const transformer = new MarkdownTransformer();
const parsed = transformer.parse(markdown);
const adf = { version: 1, ...parsed.toJSON() };
// ADF を標準出力に書き出す
process.stdout.write(JSON.stringify(adf));CI では次のように呼び出します。
# Markdown を ADF に変換して変数へ格納する
JIRA_ADF="$(node md2adf.mjs body.md)"参考までに以下のような Markdown を変換すると、ADF では見出しや箇条書きがそれぞれノードとして構造化されます。
# 見出し1
## 見出し2
- 箇条書き1
- 箇条書き2
**太字**と*斜体*と~~打ち消し線~~{"version":1,"type":"doc","content":[{"type":"heading","attrs":{"level":1,"localId":null},"content":[{"type":"text","text":"見出し1"}]},{"type":"heading","attrs":{"level":2,"localId":null},"content":[{"type":"text","text":"見出し2"}]},{"type":"bulletList","attrs":{"localId":null},"content":[{"type":"listItem","attrs":{"localId":null},"content":[{"type":"paragraph","attrs":{"localId":null},"content":[{"type":"text","text":"箇条書き1"}]}]},{"type":"listItem","attrs":{"localId":null},"content":[{"type":"paragraph","attrs":{"localId":null},"content":[{"type":"text","text":"箇条書き2"}]}]}]},{"type":"paragraph","attrs":{"localId":null},"content":[{"type":"text","marks":[{"type":"strong"}],"text":"太字"},{"type":"text","text":"と"},{"type":"text","marks":[{"type":"em"}],"text":"斜体"},{"type":"text","text":"と"},{"type":"text","marks":[{"type":"strike"}],"text":"打ち消し線"}]}]}この出力では、見出しは heading、箇条書きは bulletList、本文は paragraph として分かれています。Jira v3 はこのようなノード構造を受け取るため、単なる文字列ではなく JSON オブジェクトとして渡す必要があります。
3. API にチケット作成リクエストを送る
v3 では description に テキストではなく ADF のオブジェクト を渡します。
curl -s -X POST "https://your-domain.atlassian.net/rest/api/3/issue" \
-H "Authorization: Basic ${JIRA_BASIC_AUTH}" \
-H "Content-Type: application/json" \
--data "$(jq -n \
--arg summary "CI失敗: ${BUILD_NAME}" \
--argjson desc "$JIRA_ADF" \
'{fields: {project: {key: "OPS"}, issuetype: {name: "Bug"}, summary: $summary, description: $desc}}')"v2 との違いは、本文を --arg(文字列)ではなく --argjson(JSON オブジェクト)で渡している点です。ADF はあくまで JSON 構造なので、文字列として渡すと型エラーで弾かれます。
v3 でも認証情報の扱いは v2 と同じく注意が必要です。JIRA_BASIC_AUTH にはメールアドレスと API トークンを含めることが多いため、ログ出力を避け、Jira 側の権限もチケット作成に必要な範囲へ絞っておきます。
ハマったポイント
v3 に文字列を渡すと弾かれる
v3 の description に ADF を文字列のまま渡すと、description: Operation value must be an Atlassian Document のようなエラーで弾かれます。jq に渡すときは必ず --argjson を使い、JSON オブジェクトとして埋め込む必要があります。ここは v2 からの移行で見落としやすいポイントです。
pandoc のバージョンで jira 出力の細部が変わる
pandoc は比較的新しいバージョンで jira ライターのテーブル対応などが改善されています。古いバージョンだとテーブルがうまく変換されないことがあったため、CI イメージにインストールする pandoc のバージョンは固定しておくことをおすすめします。
# CI で pandoc のバージョンを確認しておく
pandoc --version | head -n 1まとめ
CIからJiraチケットを自動生成する際、本文の変換は API バージョンによって別物になります。v2 は Wiki 記法のテキストを渡すため pandoc の -t jira で変換し、v3 は ADF という JSON 構造を渡すため Atlaskit の MarkdownTransformer で変換しました。
今回の作業で改めて感じたのは、Jira の本文まわりは「テキストか JSON か」という前提が API バージョンで切り替わるため、最初にどちらの世界で戦っているかを確定させることが何より重要だ、という点です。同じ description というフィールド名でも中身の型が違うので、エラーメッセージだけ見ても気づきにくいのが厄介でした。
両環境を抱えているうちは v2 と v3 の変換を共通のインターフェースで切り替えられるようにしておくと運用が楽になります。
コメント