はじめに
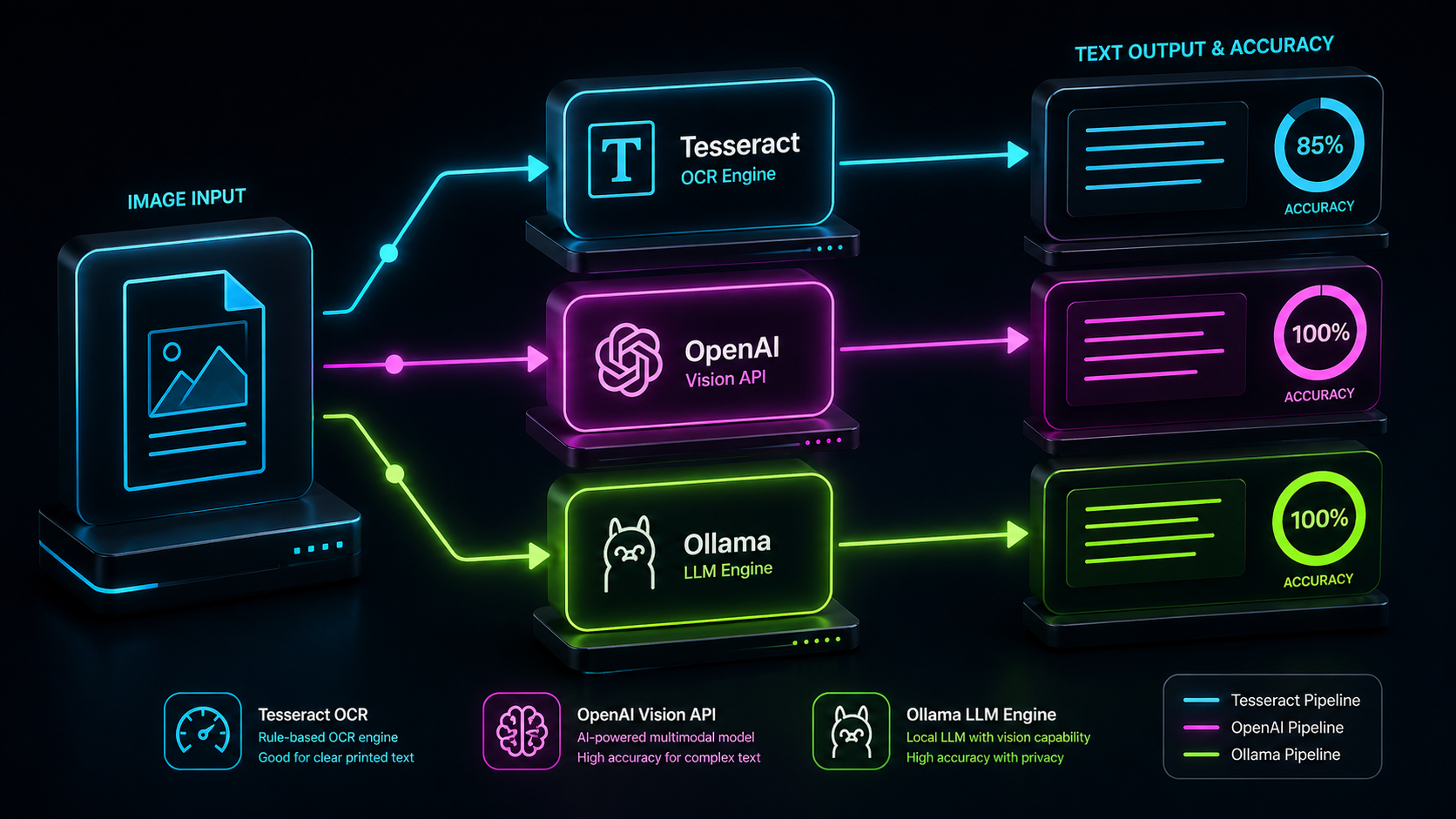
書類や手書きメモを画像からテキストとして取り込みたい場面があり、OCRとLLMの画像読み取りを両方試してみました。 OCRには無料で使えるオープンソースの tesseract を、LLMにはOpenAI APIとローカルで動作する Ollama を使い、印刷風文字と手書き風文字でそれぞれ読み取り精度を比較しました。 本記事では検証コードの解説と比較結果、用途に応じた使い分けの指針をまとめます。
Tesseract OCRとは
Tesseractは、Googleが開発・メンテナンスしているオープンソースのOCRエンジンです。 日本語を含む100以上の言語に対応しており、jpn の言語パックを追加するだけで日本語テキストの認識が可能です。 ローカルで完全にオフライン動作するため、外部APIへのコスト発生やデータ送信を避けたい用途に向いています。
Pythonからは pytesseract ラッパー経由で利用します。
使用環境
| 項目 | バージョン |
|---|---|
| Python | 3.14以降 |
| pytesseract | 0.3.x |
| Pillow | 12.x |
| openai SDK | 2.x |
| ollama SDK | 0.6.x |
| tesseract | 5.x |
| 日本語モデル | jpn(tesseract-ocr-jpn) |
事前に以下のパッケージをインストールしておく必要があります。
# Ubuntu / Debian の場合
sudo apt install tesseract-ocr tesseract-ocr-jpn
# Ollama のインストールと画像認識モデルの取得
curl -fsSL https://ollama.com/install.sh | sh
ollama pull qwen3.5:9b環境管理には uv を使用します。
# uv のインストール
curl -LsSf https://astral.sh/uv/install.sh | sh
# プロジェクト作成と依存パッケージの追加
uv init compare
cd compare
uv add openai ollama pytesseract PillowOpenAI APIを使用するには OPENAI_API_KEY 環境変数にAPIキーを設定してください。 OllamaのホストURLを変更する場合は OLLAMA_HOST 環境変数で指定します(省略時は http://localhost:11434)。
export OPENAI_API_KEY="sk-..."
export OLLAMA_HOST="http://192.168.1.100:11434" # リモートのOllamaサーバーを使う場合検証コード
以下のスクリプト(compare.py)を作成しました。
import base64
import os
import sys
import pytesseract
from ollama import Client as OllamaClient
from openai import OpenAI
from PIL import Image
def read_with_tesseract(image_path: str) -> str:
image = Image.open(image_path)
# lang="jpn" で日本語モデルを指定する
text = pytesseract.image_to_string(image, lang="jpn")
return text.strip()
def read_with_openai(image_path: str, client: OpenAI) -> str:
with open(image_path, "rb") as f:
image_data = base64.standard_b64encode(f.read()).decode("utf-8")
response = client.responses.create(
model="gpt-5-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": "この画像に書かれているテキストをそのまま読み取って出力してください。テキスト以外の説明は不要です。",
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{image_data}",
},
],
}
],
)
return response.output_text.strip()
def read_with_ollama(image_path: str, client: OllamaClient) -> str:
response = client.chat(
model="qwen3.5:9b",
messages=[
{
"role": "user",
"content": "この画像に書かれているテキストをそのまま読み取って出力してください。テキスト以外の説明は不要です。",
"images": [image_path],
}
],
)
return response.message.content.strip()
if __name__ == "__main__":
if len(sys.argv) < 2:
print("使用方法: python compare.py <画像ファイル>")
sys.exit(1)
image_path = sys.argv[1]
# OPENAI_API_KEY 環境変数を自動で読み込む
openai_client = OpenAI()
# OLLAMA_HOST 環境変数でサーバーURLを指定する
ollama_client = OllamaClient(
host=os.environ.get("OLLAMA_HOST", "http://localhost:11434")
)
print("--- Tesseract ---")
print(read_with_tesseract(image_path))
print()
print("--- OpenAI (gpt-5-mini) ---")
print(read_with_openai(image_path, openai_client))
print()
print("--- Ollama (qwen3.5:9b) ---")
print(read_with_ollama(image_path, ollama_client))ポイントをいくつか補足します。
Tesseract:lang="jpn" を指定しないと英語モデルで認識されるため、日本語がほぼ読み取れません。
OpenAI:画像はBase64エンコードしてリクエストに埋め込みます。OpenAI() インスタンス生成時に OPENAI_API_KEY 環境変数のAPIキーが自動で読み込まれます。
Ollama:画像ファイルのパスをそのまま images に渡せるため、Base64エンコードは不要です。OLLAMA_HOST 環境変数でサーバーURLを切り替えられます。
実行は次のコマンドで行います。
uv run python compare.py sample.jpg検証結果
検証用の画像は2枚とも生成AIで作成しました。同じ文章を「印刷風」と「手書き風」のテイストで生成し、認識精度の差が出やすい条件を揃えています。
印刷風文字の場合

Tesseract の結果:
本日はお足元の悪い中、
お越しいただき
ありがとうございます。OpenAI (gpt-5-mini) の結果:
本日はお足元の悪い中、
お越しいただき
ありがとうございます。Ollama (qwen3.5:9b) の結果:
本日はお足元の悪い中、
お越しいただき
ありがとうございます。印刷風文字では3つともほぼ完全に正確な読み取りができました。 Tesseractは画像の解像度が十分あれば印刷文字を安定して認識できます。
手書き風文字の場合

Tesseract の結果:
本は お足元の恵ぃ中、
お越しいただき
ありがと2ございます。OpenAI (gpt-5-mini) の結果:
本日はお足元の悪い中、
お越しいただき
ありがとうございます。Ollama (qwen3.5:9b) の結果:
本日はお足元の悪い中、
お越しいただき
ありがとうございます。手書き風文字ではTesseractが苦戦し、文字の誤認識が目立ちました。 「本日」が「本は」、「悪い」が「恵ぃ」、「ありがとう」が「ありがと2」のように形の近い文字や数字への誤認識が発生しています。 一方、OpenAIとOllamaはどちらも完全に正確に読み取ることができました。 Tesseractは印刷文字向けに設計されているため、手書き特有の崩れや個人差への対応が難しいようです。
使い分けの指針
| 観点 | Tesseract | OpenAI | Ollama |
|---|---|---|---|
| コスト | 無料 | APIコスト発生(トークン課金) | 無料(ローカル実行) |
| 処理速度 | 高速(ローカル処理) | 通信オーバーヘッドあり | モデルサイズによる |
| 印刷文字の精度 | 高い | 高い | 高い |
| 手書き文字の精度 | 低〜中程度 | 高い | 高い |
| オフライン動作 | 可能 | 不可(API通信が必要) | 可能 |
| プライバシー | 画像がローカルに留まる | 画像を外部APIへ送信 | 画像がローカルに留まる |
| 導入のしやすさ | パッケージインストールのみ | APIキーの取得・管理が必要 | Ollamaのセットアップが必要 |
コストをかけずに大量の印刷文書をテキスト化するならTesseractが適しています。 精度を優先しつつプライバシーも守りたい場合はOllamaが有効な選択肢です。 手書き文字や崩れた文字を高精度で処理したい場合はOpenAIが有効です。 個人情報を含む画像を扱う場合は、外部APIへの送信が許容できるかも確認が必要です。
まとめ
TesseractとOpenAI・Ollamaで日本語テキストの読み取り精度を比較しました。 印刷風文字では3つとも十分な精度が出ましたが、実際の手書き文字ではTesseractが苦戦し、OpenAIとOllamaはどちらも完全に正確な読み取りができました。 コスト・プライバシー・精度の要件に応じて使い分けることで、それぞれのメリットを活かせます。参考になれば幸いです。


コメント